Great technology links — Great learning at zero cost — June 2024
Comparing the Predictive capabilities of AI Engines
Introduction
In this edition of Great Technology Links, we will focus on the topic of Artificial Intelligence (AI). We discuss four products rather than the usual three and will compare their outputs and, in the process, highlight certain limitations of these tools and of AI in general.
AI technology can be divided into two categories:
- Generative — This category describes AI engines that are able to generate output based on prompts. Examples of such output include text, graphics, audio, and videos. For example, in this study, the graphic generated by CoPilot is an example of generative output.
- Predictive — These AI models ingest massive amounts of data and, based on the source material, provide knowledge-based (expert-systems) output or extrapolate into the future.
The analysis focuses more on the predictive aspects of the evaluated AI engines.
The AI Engines
The four AI engines that were analysed are:
- Anthropic Claude : https://claude.ai
- Google Gemini : https://gemini.google.com
- Microsoft CoPilot : https://www.bing.com/chat
- OpenAI ChatGPT : https://chatgpt.com

Free vs Paid
All the engines described here are free but also have a paid tier. Here is a breakdown of some of the differences:
- AI Engine Model — The paid tier may use a more advanced model, making it faster, more accurate, and overall better.
- LLM Training Data Span — If the free free is an older version, it would have been trained on less recent data. This implies that it may not have information on events that occurred after its training data cut-off.
- Performance — The free tier could be slower and might be limited in the length /depth of the output it produces.
- Other Limitations — The free tier may have other limitations, such as the number of exchanges allowed per hour or day and the absence of features to fine-tune the engine’s output.
Limitations in Accuracy and Understanding
AI engines rely on statistical and computational techniques to generate outputs, and these outputs may not always be accurate. All the AI engines referenced in this study carry a disclaimer to warn users of this limitation.
The inaccuracy happens because of:
- Limited Understanding: Unlike experts, AI engines don’t truly “understand” the information they process. They identify patterns through statistical analysis, but they can’t grasp the deeper meaning or core concepts.
- Limited Reasoning: AI engines struggle with tasks that require common sense reasoning, such as applying their knowledge to unexpected situations or making judgments based on incomplete information. Experts can use their knowledge and experience to solve problems in novel ways, even if they haven’t encountered the exact situation before.
- Susceptibility to Bias: AI engines can inherit biases from the data they’re trained on. This can lead to inaccurate or prejudiced outputs, something a human expert can potentially avoid through critical thinking.
Testing Methodology
We sourced questions from the book, AWS Certified Cloud Practitioner Study Guide With 500 Practice Test Questions: Foundational (CLF-C02) Exam (Sybex Study Guide), 2nd Edition Affiliate Link. This book, which comes with 500 practice questions, is highly recommended for those preparing for AWS’s Certified Cloud Practitioner foundational certification. Sample questions were taken from the first three chapters of the book.
Two questions were generated by the author of this study, with the second question being a continuation of the first. The idea was to test the AI engine’s ability to delve deeper into the topic. The follow-up question asked the AI engine to generate a schematic of a standard concept.
The decision to test the AI on this subject matter was based on:
- The material is a foundational level technical topic and entry-level technical. Since these are questions for a multiple choice exam, there is only one correct answer.
- The Cloud Practitioner Certification was launched in 2017, with version 2 released in 2023. All these engines would have had the opportunity to be trained on material related to this topic. The questions fed to the AI were version-neutral.
- Aside from third party content, AWS has a vast amount of documentation on its site, likely more than a human being can read through, making it ideal for a predictive AI engine. The AWS site is systematically catalogued.
- The material is factual, meaning there should not be any bias in the answers.
Each question was entered them into a text editor and after which it was copied into the prompt of each AI engine. This ensured that transcription mistakes would be eliminated.
The answer were evaluated for:
Scoring (Accuracy)
- 1 point was awarded if a correct answer was given (with the exception of one question where the author did not agreed with the answer in the book).
- 0 points were awarded if the answer was incorrect.
Scoring (Insight)
- 1 point was awarded if the AI engine explained why the other options were not correct.
Until the AI completed its output focus was retained on the product. This was done to eliminate any functionality built into the products which would cause the engine to stop processing as soon as the browser window lost focus.
Where the option was available, we selected the more precise answer.
The tests were conducted during May 2024.
Results
Scoring (Accuracy)
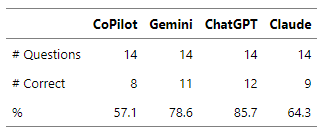
It’s clear that the current generation of AI engines isn’t reliably accurate. If these engines were to take certification tests, three out of four would fail, given that the typical passing score for such exams is 80%.
Additional Statistics generated from Computed on AI-Therapy Statistics

Scoring (Insight)
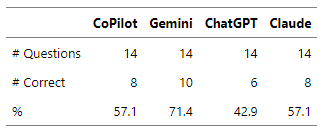
The interpretability of this metric is subjective, implying that different evaluators may derive slightly varying scores. The raw data is available for download, allowing for independent interpretation and analysis. It’s crucial to note that a low score does not necessarily reflect the inaccuracy of the AI model. For instance, ChatGPT’s lowest Insight score coupled with its highest Accuracy score merely suggests that the model provided the correct response without elaborating on the incorrectness of alternative answers.
Combined > 2 (Accuracy)
# Questions: 8
# Correct: 14
%: 57.1
Imagine a system that asks multiple AI engines the same question. It then analyzes their answers and picks the answer that most of the engines agree on (like a majority vote). This “majority-based” approach wasn’t more accurate to the performance of the single worst-performing AI engine.
Combined >= 2 (Accuracy)
# Questions: 8
# Correct: 12
%: 85.7
This statistic incorporates even split votes (2 out of 4 engines disagreeing) as correct answers. While this approach improved the overall performance, it did not surpass the accuracy achieved by the single most effective AI engine.
Conclusions
Limitations of Generalizability:
- This study focused on a narrow domain, and the performance of AI engines cannot be generalized to other subject matters without further investigation.
- The observed superiority of some engines on specific questions may be due to better training data on that particular topic rather than overall superiority.
- Combining outputs from multiple engines did not improve overall quality, suggesting a lack of synergy.
Data Reliability and Sample Size:
- While some engines parsed questions effectively and generated relevant answers, accuracy was inconsistent. Answers might be well-articulated but factually incorrect, as evidenced by CoPilot’s example (row 12 in source data).
- A larger sample size of questions is necessary to obtain statistically robust results about the true capabilities of these engines.
Potential Applications:
- The “insight” feature, which describes the reasoning behind the answer (not generated by all AI engines), can serve as an effective learning tool, provided the answer has been validated. These tools have the potential to reinforce existing knowledge.
Future Research Directions:
- Further studies with diverse question sets across various domains are needed to assess the generalizability of performance.
- An investigation into the source and quality of the training data utilized by various engines could shed light on the observed differences in performance. Alternatively, these engines could be evaluated against a controlled corpus of validated data, which would guarantee that no erroneous data influences the results.
Data Source
The questions, replies and scoring can be downloaded from: GTL Github Repo.
If you discover a link for inclusion in the Great technology links — Great learning at zero cost, share it as a comment.
Only forward a link if:
- You have personally verified it by consuming and following the content. Don’t simply forward an email you found in your inbox or on social media.
- If free. Free means without restrictions, without limitations, and without having to take any action to use the content.
- It is about technology.
- It is in English.
- It is Legit.
